Seamless Provisioning and Decommissioning of Trusted Execution Environment-based Applications in the Cloud1
Abstract
With the proliferation of Trusted Execution Environments (TEEs) such as Intel SGX, a number of cloud providers will soon introduce TEE capabilities within their offering (e.g., Microsoft Azure). The integration of SGX within the cloud considerably strengthens the threat model for cloud applications. However, cloud deployments depend on the ability of the cloud operator to add and remove application dynamically; this is no longer possible given the current model to deploy and provision enclaves that actively involves the application owner. In this paper, we propose ReplicaTEE, a solution that enables seamless commissioning and decommissioning of TEE-based applications in the cloud. ReplicaTEE leverages an SGX-based provisioning service that interfaces with a Byzantine Fault-Tolerant storage service to securely orchestrate enclave replication in the cloud, without the active intervention of the application owner. Namely, in ReplicaTEE, the application owner entrusts application secret to the provisioning service; the latter handles all enclave commissioning and decommissioning operations throughout the application lifetime. We analyze the security of ReplicaTEE and show that it is secure against attacks by a powerful adversary that can compromise a large fraction of the cloud infrastructure. We implement a prototype of ReplicaTEE in a realistic cloud environment and evaluate its performance. ReplicaTEE moderately increments the TCB by LoC. Our evaluation shows that ReplicaTEE does not add significant overhead to existing SGX-based applications.
I Introduction
With the recent proliferation of Trusted Execution Environments (TEEs) such as Intel SGX, a number of cloud providers will soon introduce TEE capabilities within their offering (e.g., Microsoft Azure [8]). Using TEEs within the cloud allows the design of secure applications (e.g, [9, 14, 13]) that can tolerate malware and system vulnerabilities, as application secrets are shielded from any privileged code on the same host.
Although the integration of SGX within the cloud considerably strengthens the threat model for cloud applications, the current model to deploy and provision an enclave, prevents the cloud operator from adding or removing enclaves dynamically—thus effectively hampering elasticity. Namely, elastic deployment assumes that the cloud operator can swiftly add or remove replicas of an application (be it a VM or an enclave) depending on factors such as current load or throughput. Yet, the deployment model of SGX prevents a cloud provider to dynamically start new enclaves. That is, SGX enclaves bear no secrets when deployed; secrets are securely provisioned to the enclave by the application owner after he attests the application code and makes sure that it runs untampered in an enclave on an SGX-enabled platform. In a nutshell, dynamic deployment for TEE-based applications in the cloud requires the application owner to be online throughout the whole application lifetime. The only alternative for an application owner is to entrust the secrets of his application to the cloud provider. This, however, obviates the shift to deploy SGX enclaves in the cloud since it exposes all application secrets to malware that may potentially penetrate the cloud infrastructure.
Although the community features a number of studies on SGX security in the cloud [11, 2, 3], no previous work has addressed the problem of enabling seamless commissioning and decommissioning of enclaves in the cloud. Here, there are a number of challenges to overcome. One the one hand, such a service should remove the need of an online application owner. On the other hand, it should warrant owners the same security provisions of the current provisioning model, where owners attest and provision secrets to their applications.
Further, the number of running replicas of a given applications must be controlled, since unrestricted enclave replication may amplify the effectiveness of forking attacks [2]. In a forking attack, the adversary runs several instances of an application and provides them with different state or inputs to influence their behavior. For example, consider an authentication service running in SGX enclaves. To mitigate brute-force attacks, the service may use rate-limiting and, for example, allow up to password trials per account. An adversary that manages to compromise the cloud infrastructure could launch several instances of the service in order to increase the number of trials per account and brute-force passwords. A service that automatically provisions enclaves must, therefore, control the number of running enclaves for a given application at all times, despite malware that may penetrate the cloud infrastructure.
In this paper, we propose ReplicaTEE, a solution that enables dynamic enclave commissioning and decommissioning for TEE-based applications in the cloud. ReplicaTEE leverages a distributed SGX-based provisioning service that interfaces with a Byzantine Fault-Tolerant (BFT) storage service to orchestrate secure and dynamic enclave replication in the cloud. Namely, in ReplicaTEE, the application owner entrusts application secrets to the provisioning service and can go offline. The provisioning service is a distributed service that runs entirely in SGX enclaves and assists the cloud to add or remove enclaves of an application on behalf of the application owner. Application secrets are, therefore, shielded away from malware that penetrates the cloud, as they are securely transferred from the application owner to the provisioning service, onto application enclaves.
The provisioning service also controls the number of running enclaves for a given application, in order to mitigate forking attacks against victim applications. Yet, a forking attack against the provisioning service itself, may allow an adversary to run an arbitrary number of enclaves of a victim application (and therefore launch a forking attack against the victim). We prevent forking attacks against the provisioning service by leveraging a distributed BFT storage service that guarantees dependable storage despite compromise of a fraction of its nodes. We design the provisioning service to duly store onto the storage service any operation regarding commissioning and decommissioning enclaves so to constantly control the number of running enclaves for each application. As a result, ReplicaTEE protects confidentiality of application secrets against an adversary that can compromise privileged code on the cloud’s platforms. Forking attacks against applications are mitigated as long as the number of compromised nodes in the storage service remains below a tuneable threshold.
We design ReplicaTEE to be compliant with the existing Intel SGX SDK. We also implement a prototype of ReplicaTEE in a realistic cloud environment and evaluate its performance. Our evaluation shows that ReplicaTEE increments the TCB by approximately 800 Lines of Code (LoC) and does not add significant overhead to existing SGX-based applications.
II Model & Overview
II-A System Model
We consider a scenario where a cloud provider manages a set of SGX-enabled platforms. Application owners can upload code to be executed on such platforms. Applications could either run computation on behalf of their owners such as a map-reduce service [13], or provide public functionalities such as an online password-strengthening service [9].
Deployment. In a real-world deployment of ReplicaTEE, application owners would acquire (e.g., rent) VMs at the cloud and split the logic of their applications (e.g., by using available tools [10]) in sensitive code to be run in an enclave and non-sensitive code that can run inside the VM. Therefore, each of the cloud platforms would host VMs from different tenants and each VM would have one or more enclaves. However, for the sake of simplicity, we assume in this paper that the entire application code is executed in enclaves. Given this assumption, each of the cloud platforms hosts multiple enclaves belonging to different owners.
Dynamic Provisioning. In line with current elastic cloud settings, we assume that multiple instances of the same application enclave may dynamically be started or shut down. In the following, we use the term application enclave to refer to an instance of application code running in an enclave, and we use application to denote the logical entity spanning multiple enclaves running the same code.
We are agnostic on how the decision to add or remove application enclaves for a given application is made. For example, this decision may be taken by the cloud for reasons such as load, throughput, or efficient resource utilization. Alternatively, the application itself may monitor its performance and, when needed, ask the cloud to add or remove instances.
II-B Threat Model
The goal of the adversary that we consider is two-fold. On the one hand, the adversary is interested to leak the secrets of the applications. On the other hand, the adversary might also be interested in deploying a large number of application enclaves in order to amplify the effect of a forking attack against a victim application.
The adversary can compromise privileged code on a node and we denote that node as compromised. Throughout the paper, we include SGX in the TCB and therefore assume that the adversary cannot compromise SGX components (e.g., system or application enclaves) on the compromised node. Namely, we do not take into account attacks specific to SGX, such as the ones that exploit side-channels [4]. Measures to mitigate attacks against SGX [12, 7] are orthogonal to ReplicaTEE and could be deployed alongside our solution.
Although we do not consider DoS attacks in this paper, we assume that the adversary controls the network and as such controls the scheduling of all transmitted messages.
II-C Overview
To the best of our knowledge, there is no mechanism that enables enclave replication in the cloud in a way that is transparent to the application owner. Clearly, a cloud provider can autonomously start an arbitrary number of application enclaves as long as they do not require any secret material. However, if the enclavesrequires a secret key (e.g., for applications like Talos [1] or SecureKeeper [5]), the enclave owner must be involved in the enclave deployment process for attestation and secret provisioning.
Alternatively, application owners may entrust the secrets of their applications to the cloud. Nevertheless, this option is in sharp contrast with the settings of SGX where enclave secrets are to be hidden from any other software on the host. In other words, if application owners trust the cloud with handling their secret data, then SGX becomes unnecessary.
Strawman solution. A strawman solution to the problem that we consider would be to create a provisioning service that runs entirely in an SGX enclave and acts on behalf of the application owner when the cloud must deploy new application instances. One may have a single provisioning service per cloud, or a provisioning service serving multiple clouds.
Here, an application owner uploads the code of its application to the cloud. At the same time, the owner attests the provisioning service, call it Enclave Management Service (EMS), and transfers to it the hash of the application along with the application secrets. When a new application instance needs to be started, the cloud sets up the instance and asks EMS for attestation and secret provisioning. As a result, the cloud and EMS can deploy new instances of an application enclave while the owner is no longer required to be online. Further, application secrets are shielded from the cloud (and from malware that penetrates the cloud) since secrets are securely transferred from the application owner, to EMS (which runs in an enclave) to the target application (which runs in an enclave). However, this strawman solution suffers from the following shortcomings.
- Highly availability.
EMS must be highly available because no new application instances can be started when EMS is down, and fast commissioning and decommissioning of enclaves is key to the elastic operations of the cloud provider.
- Forking attacks.
EMS should not allow for unrestricted deployment of instances. For example, an adversary may compromise the cloud and deploy a large number of instances of a victim application in order to mount a forking attack. The provisioning service must, therefore, control at all times the number of deployed instances of a given application; if this number reaches a given threshold, no further deployment requests should be served.111 The threshold may be set by the application owner as part of the deployment policy that usually allows owners to decide parameters such as maximum load per instance, geographical deployment restrictions, etc. Controlling the number of running application enclaves requires EMS to keep state. Otherwise, a forking attack against EMS itself, would allow the adversary to launch an arbitrary number of application instances to, in turn, mount a forking attack against the victim application. We note that monotonic counters available to SGX enclaves222 https://software.intel.com/en-us/sgx-sdk-dev-reference-sgx-create-monotonic-counter may be suitable for centralized applications to keep state. Monotonic counters, however, are not suited to keep state of an application (like EMS) distributed across different hosts. Similarly, ROTE [11] is a distributed solution to keep state of single-enclave applications and cannot be used when state must be synchronized across enclaves. The challenge is, therefore, how to keep a consistent state across all of the EMS enclaves.
- Small TCB.
The only effective and workable way to securely maintain state for an application that spans multiple instances, while assuming a potentially malicious OS, would be to leverage a reliable consensus mechanism. One option would be to fit the consensus logic within EMS. However, this design choice leads to a large code-base which, in turn, becomes a large attack surface. That is, a large footprint of the enclave code that implements EMS, essentially weakens the assumption that enclaves cannot be compromised.
We tackle the above challenges as depicted in Figure 1. We design ReplicaTEE as a two-tiered approach. At the first tier, EMS (i) acts on behalf of application owners and supports the cloud in commissioning and decommissioning application enclaves, and (ii) mitigates forking attacks against application enclaves by controlling the number of running enclaves for a given application. EMS is a distributed SGX-based service that leverages a master-slave approach to ensure high availability. Master-slave is arguably the simplest distributed architecture and its small code-base allow us to fit its entire logic within an enclave. Master and slaves exchange beacons to monitor one another; in case the master fails, one of the slaves becomes the new master.
At the second tier, a BFT Storage Service (BSS) provides EMS with reliable storage and allows to prevent forking attacks against EMS itself (which, in turn, may lead to forking attacks against applications). We opt to separate EMS from the consensus logic and create BSS as a dedicated service in order to keep EMS code-base small. Yet, the consensus logic is complex and fitting it entirely in an enclave may open the door to exploits. A better option is to design consensus that leverages the isolated execution feature made available by SGX while, at the same time, keeps the enclave code at bare minimum. When instantiating the consensus service, we therefore resort to TEE-based consensus protocols like MinBFT [15] that can tolerate up to out of faulty nodes but still have a very small TCB ( LoC).333 Traditional consensus protocols that do not leverage TEEs can only tolerate out of faulty nodes. Nevertheless, as the consensus logic is now split between enclave and non-enclave code, we must account for an attacker that compromises the part of the logic running outside of SGX. In other words, the nodes of the consensus service may now become Byzantine. We show that by carefully designing the interaction between EMS and BSS, a master-slave application like EMS can be shielded from forking attacks.
A note on enclave termination. The above overview covers enclave provisioning. However, controlling the number of running enclaves for an application, requires EMS to also be aware of the enclaves that terminate. We note that, given our threat model, there is no means for EMS to tell if an application enclave has been stopped by . We tackle this issue by implementing a lease-based approach. When provisioned, enclaves receive an end-of-lease timestamp and should stop running if that time is reached and EMS has not renewed the lease. In other words, we do not rely on the cloud to terminate enclaves. The length of a lease is a tunable parameter and represents a trade-off between security and overhead due to lease renewal.
III Performance Analysis
 |
 |
 |
We deployed the storage service of ReplicaTEE on five identical servers with SGX supports. Each server is equipped with Intel Xeon E3-1240 V5 (8 vCores @3.50GHz) and 32 GiB RAM. The EMS instances were deployed on a machine with Intel Core i5-6500 (4 Cores @3.20GHz) and 8 GiB RAM. All these machines are equipped with SGX to run enclaves and are connected with a 1Gbps switch in a private LAN network. We argue that this setting emulates a realistic cloud deployment scenario where the compute servers and their corresponding storage servers communicate over the cloud’s private LAN (e.g., Amazon AWS and S3).
We instantiate the atomic storage service of ReplicaTEE using MinBFT. Our implementation of MinBFT uses 2 interface functions (, [15]). In our evaluation, we relied on HMAC-SHA256 to achieve authentication between replicas and clients [6, 15].
In what follows, we evaluate the performance of ReplicaTEE. Namely, we measure the latency incurred in the provisioning of enclaves and in termination, suspension, resumption and lease renewal. Note that we do not evaluate the overhead incurred in the initial setup phase of EMS and the initial code upload by application owners, since the setup is carried out only once and the overhead for application owners to upload their code to the cloud is not particular to ReplicaTEE and is incurred by all applications that leverage cloud-based SGX deployments.
We also measure the latency incurred in the provisioning of enclaves with respect to the achieved throughput. We measure the throughput as follows. The master EMS enclave invokes operations in a closed loop, i.e., enclaves may have at most one pending operation. We require that the master EMS enclave performs a series of back-to-back operations (requests) and measure the end-to-end time taken by each operation. We then increase the number of provisioning requests in the system until the aggregated throughput is saturated.
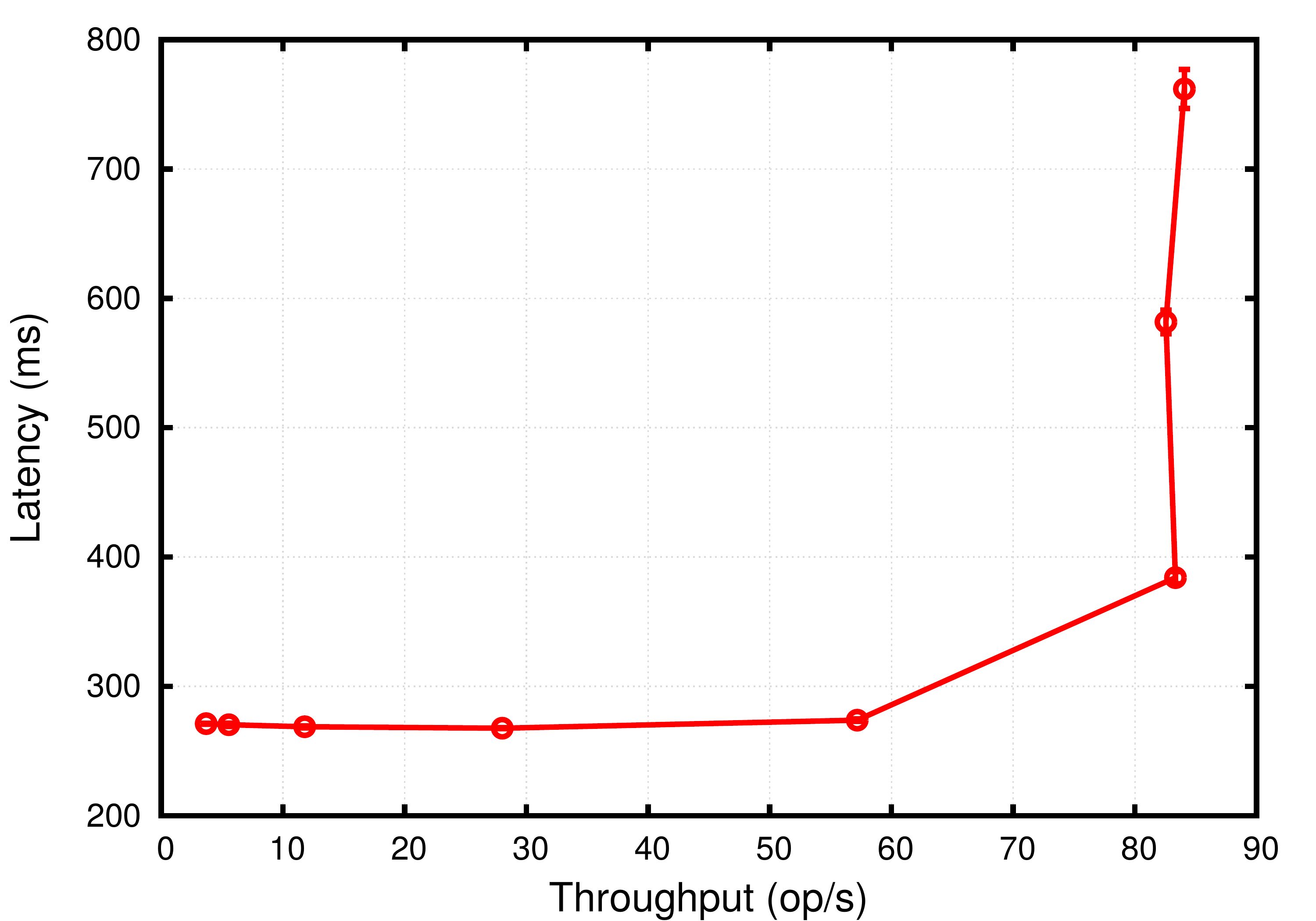
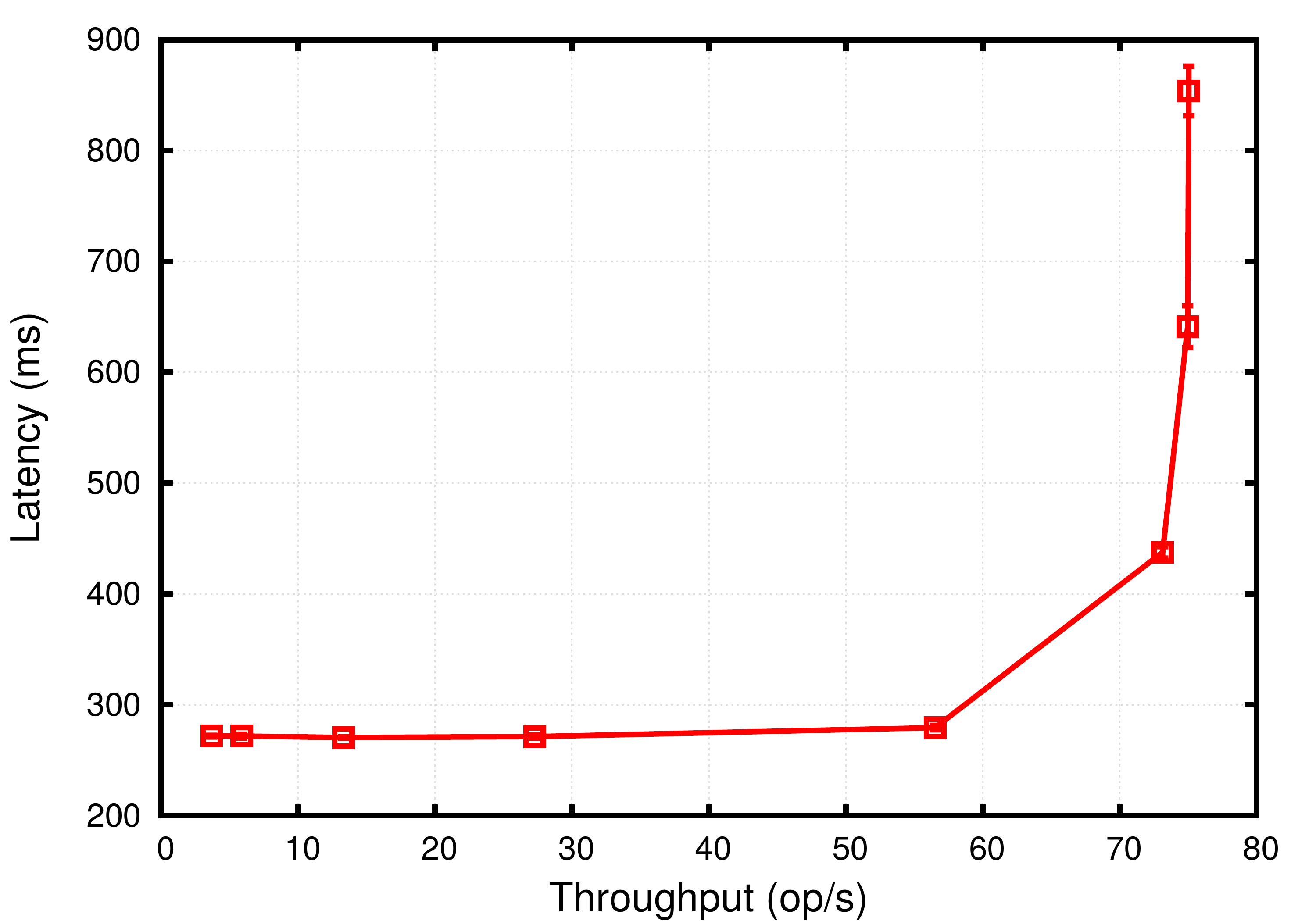
Enclave Provisioning. In Figures 2(a) and 2(b), we evaluate the throughput vs latency for the enclave provisioning process given different storage failure threshold . We see that when (3 storage servers), the system achieves a peak throughput of op/s with a latency of ms. On the other hand, when (5 storage servers), the latency remains almost the same, while the peak throughput is reduces to op/s. Our findings suggest that the remote attestation process is the dominant factor in the operation latency. Notice that even if increasing the fault-tolerance threshold of BSS reduces the peak throughput (since it requires more communication rounds), it has limited impact on the witnessed latency.
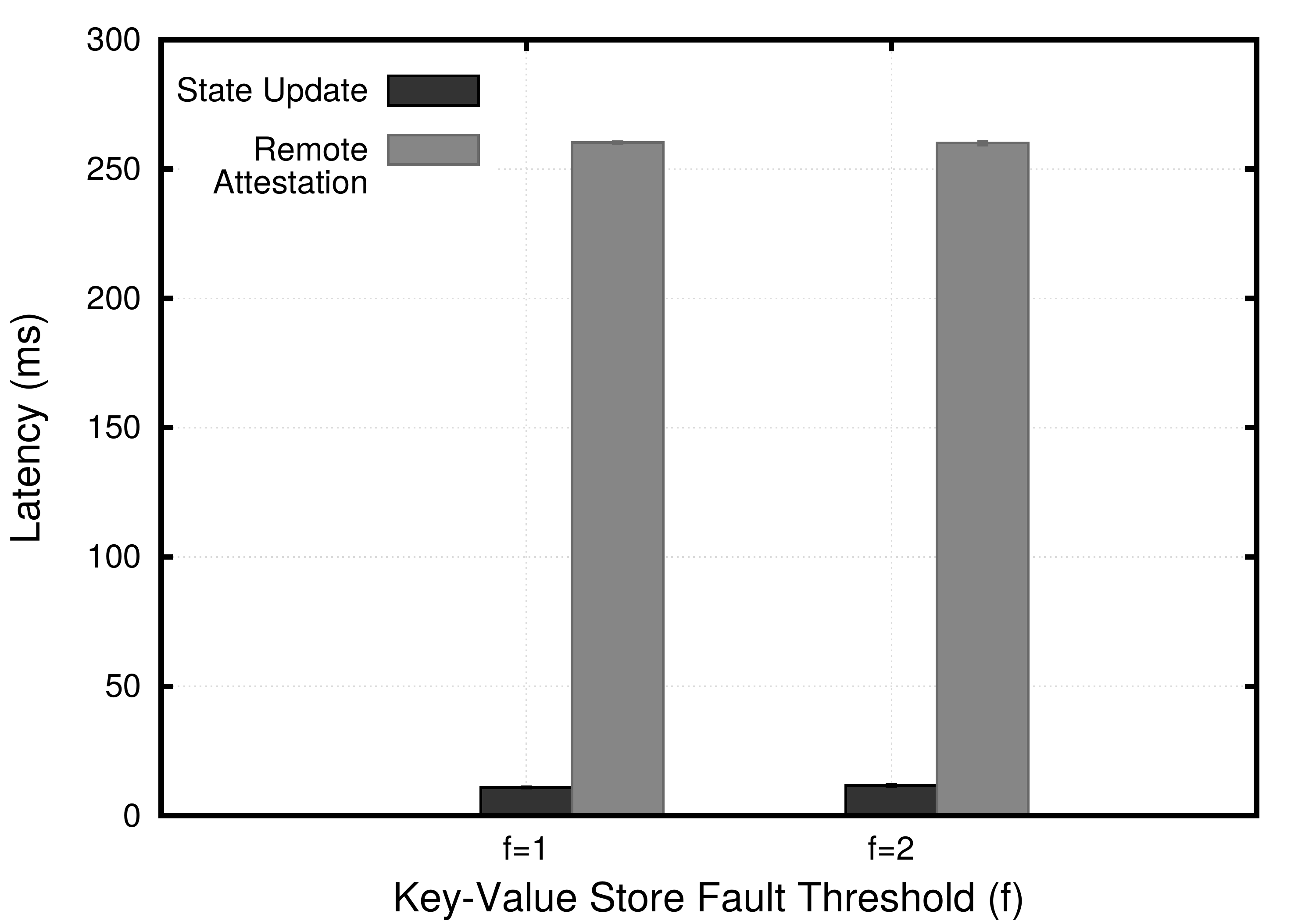
In Figure 2(c), we further measure the constituent latencies incurred in the enclave provisioning process. In both cases when and , we see that the time for remote attestation is around ms while the state update only takes ms without noticeable difference in either cases. Namely, the state update only comprises up to % of the whole provision process even when .
Termination/Suspension/Resumption/Renewal Requests. Recall that termination, suspension, resumption, and renewal requests basically consist of the EMS enclave updating the records corresponding to the target enclave on the storage service. These requests are practically instantiated by a PUT request issued by the EMS primary enclave to update the associated record. Such requests only take 0.86 ms with a peak throughput of op/s or op/s when or , respectively.
References
- [1] (2017)TaLoS: Secure and Transparent TLS Termination inside SGX Enclaves. Technical reportTechnical Report 2017/5, Imperial College London. Cited by: §II-C.
- [2] (2017)Rollback and forking detection for trusted execution environments using lightweight collective memory. In International Conference on Dependable Systems and Networks, DSN, pp. 157–168. Cited by: §I, §I.
- [3] (2017)Software grand exposure: SGX cache attacks are practical. In 11th USENIX Workshop on Offensive Technologies (WOOT 17), Vancouver, BC. External Links: LinkCited by: §I.
- [4] (2017)Software grand exposure: SGX cache attacks are practical. In USENIX Workshop on Offensive Technologies (WOOT), Cited by: §II-B.
- [5] (2016)SecureKeeper: confidential zookeeper using intel SGX. In International Middleware Conference, pp. 1–14. Cited by: §II-C.
- [6] (2002)Practical byzantine fault tolerance and proactive recovery. ACM Transactions on Computer Systems (TOCS)20 (4), pp. 398–461. Cited by: §III.
- [7] (2017)Strong and efficient cache side-channel protection using hardware transactional memory. In USENIX Security Symposium, pp. 217–233. Cited by: §II-B.
- [8] (2017)Introducing Azure confidential computing. Note: https://azure.microsoft.com/en-us/blog/introducing-azure-confidential-computing/Cited by: §I.
- [9] (2017)Protecting web passwords from rogue servers using trusted execution environments. In International Conference on World Wide Web, WWW, pp. 1–16. Cited by: §I, §II-A.
- [10] (2017)Glamdring: automatic application partitioning for intel SGX. In USENIX Annual Technical Conference, (USENIX ATC), pp. 285–298. Cited by: §II-A.
- [11] (2017)ROTE: rollback protection for trusted execution. In USENIX Security Symposium, USENIX Security, pp. 1289–1306. Cited by: §I, item Forking attacks..
- [12] (2017)Varys: protecting SGX enclaves from practical side-channel attacks. In USENIX Annual Technical Conference, (USENIX ATC), pp. 227–240. Cited by: §II-B.
- [13] (2015)VC3: trustworthy data analytics in the cloud using SGX. In IEEE Symposium on Security and Privacy, S&P, pp. 38–54. Cited by: §I, §II-A.
- [14] (2016)S-NFV: securing NFV states by using SGX. In International Workshop on Security in Software Defined Networks & Network Function Virtualization, SDN-NFV@CODASPY, pp. 45–48. Cited by: §I.
- [15] (2013-01)Efficient Byzantine fault-tolerance. IEEE Transactions on Computers. External Links: LinkCited by: §II-C, §III.
1. This blog article is an excerpt of the eletronic preprint available at https://arxiv.org/abs/1809.05027. The full article is available as C. Soriente, G. Karame, W. Li and S. Fedorov, "ReplicaTEE: Enabling Seamless Replication of SGX Enclaves in the Cloud," 2019 IEEE European Symposium on Security and Privacy (EuroSandP), Stockholm, Sweden, 2019, pp. 158-171. URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8806748&isnumber=8806708
2. The second author has been supported by the CyberSec4Europe European Union’s Horizon 2020 research and innovation programme under grant agreement No 830929.