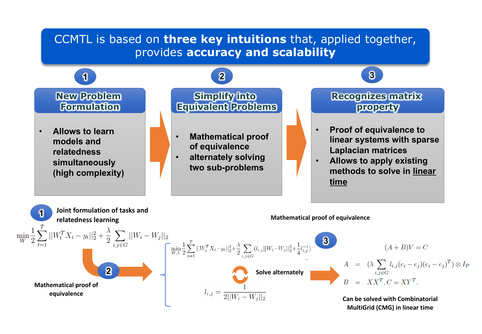
")

A Study on Ensemble Learning for Time Series Forecasting and the Need for Meta-Learning
Time series forecasting estimates how a sequence of observations continues into the future. In this blog post, we discuss the performance of ensemble methods for time series forecasting. We obtained our insights from conducting an experiment that compared a collection of 12 ensemble methods for time series forecasting, their hyperparameters and the different strategies used to select forecasting models. Furthermore, we will describe our developed meta-learning approach that automatically selects a subset of these ensemble methods (plus their hyperparameter configurations) to run for any given time series dataset.