MetaBags: Bagged Meta-Decision
Trees for Regression1
Abstract
Methods for learning heterogeneous regression ensembles have not yet been proposed on a large scale. Hitherto, in classical ML literature, stacking, cascading and voting are mostly restricted to classification problems. Regression poses distinct learning challenges that may result in poor performance, even when using well established homogeneous ensemble schemas such as bagging or boosting. In this paper, we introduce MetaBags, a novel stacking framework for regression. MetaBags learns a set of meta-decision trees designed to select one base model (i.e. expert) for each query, and focuses on inductive bias reduction. Finally, these predictions are aggregated into a single prediction through a bagging procedure at meta-level. MetaBags is designed to learn a model with a fair bias-variance trade-off, and its improvement over base model performance is correlated with the prediction diversity of different experts on specific input space subregions. An exhaustive empirical testing of the method was performed, evaluating both generalization error and scalability of the approach on open, synthetic and real-world application datasets. The obtained results show that our method outperforms existing state-of-the-art approaches.
Keywords:
Stacking Regression Meta-Learning Landmarking.1 Introduction
Ensemble refers to a collection of several models (i.e., experts) that are combined to address a given task (e.g. obtain a lower generalization error for supervised learning problems) [24]. Ensemble learning can be divided in three different stages [24]: (i) base model generation, where multiple possible hypotheses to model a given phenomenon are generated; (ii) model pruning, where of those are kept and (iii) model integration, where these hypotheses are combined, i.e. . Naturally, the process may require large computational resources for (i) and/or large and representative training sets to avoid overfitting, since is also learned on the training set, which was already used to train the base models in (i). Since the pioneering Netflix competition in 2007 [1] and the introduction of cloud-based solutions for data storing and/or large-scale computations, ensembles have been increasingly used in industrial applications. For instance, Kaggle, the popular competition website, where, during the last five years, 50+% of the winning solutions involved at least one ensemble of multiple models [21].
Ensemble learning builds on the principles of committees, where there is typically never a single expert that outperforms all the others on each and every query. Instead, we may obtain a better overall performance by combining answers of multiple experts [28]. Despite the importance of the combining function for the success of the ensemble, most of the recent research on ensemble learning is either focused on (i) model generation and/or (ii) pruning [24].
Model integration approaches are grouped in three clusters [30]: (a) voting (e.g. bagging [4]), (b) cascading [18] and (c) stacking [33]. In voting, the outputs of the ensemble is a (weighted) average of outputs of the base models. Cascading iteratively combines the outputs of the base experts by including them, one at a time, as another feature in the training set. Stacking learns a meta-model that combines the outputs of all the base models. Voting relies on base models to have complementary expertise, which is an assumption that is rarely true in practice. On the other hand, cascading is typically too time-consuming to be put in practice, since it involves training of several models in a sequential fashion.
Stacking relies on the power of the meta-learning algorithm to approximate . Stacking approaches are of two types: parametric and non-parametric. The first (and most common [21]) assumes a (typically linear) functional form for , while its coefficients are either learned or estimated [7]. The second follows a strict meta-learning approach [3], where a meta-model for is learned in a non-parametric fashion by relating the characteristics of problems (i.e. properties of the training data) with the performance of the experts. Notable approaches include instance-based learning [32] and decision trees [30]. However, novel approaches for model integration in ensemble learning are primarily designed for classification and, if at all, adapted later on for regression [30, 32, 24]. While such adaptation may be trivial in many cases, it is noteworthy that regression poses distinct challenges.
Formally, we formulate a regression problem as the problem of learning a function
| (1) |
where denotes the true unknown function which is generating the samples’ target variable values, and denotes an approximation dependent on the feature vector and an unknown (hyper)parameter vector . One of the key differences between regression and classification is that for regression the range of is apriori undefined and potentially infinite. This issue raises practical hazards for applying many of the widely used supervised learning algorithms, since some of them cannot predict outside of the target range of their training set values (e.g. Generalized Additive Models (GAM) [20] or CART[6]). Another major issue in regression problems are outliers. In classification, one can observe either feature or concept outliers (i.e. outliers in and ), while in regression one can also observe target outliers (in ). Given that the true target domain is unknown, these outliers may be very difficult to handle with common preprocessing techniques (e.g. Tukey’s boxplot or one-class SVM [9]). Although the idea of training different experts in parallel to subsequently combine them seems theoretically attractive, the abovementioned issues make it difficult in practice, especially for regression. In this context, stacking is regarded as a complex art of finding the right combination of data preprocessing, model generation/pruning/integration and post-processing approaches for a given problem.
In this paper, we introduce MetaBags, a novel stacking framework for regression. MetaBags is a powerful meta-learning algorithm that learns a set of meta-decision trees designed to select one expert for each query thus reducing inductive bias. These trees are learned using different types of meta-features specially created for this purpose on data bootstrap samples, whereas the final meta-model output is the average of the outputs of the experts selected by each meta-decision tree for a given query. Our contributions are threefold:
- 1.
A novel meta-learning algorithm to perform non-parametric stacking for regression problems with minimum user expertise requirements.
- 2.
An approach for turning the traditional overfitting tendency of stacking into an advantage through the usage of bagging at the meta-level.
- 3.
A novel set of local landmarking meta-features that characterize the learning process in feature subspaces and enable model integration for regression problems.
In the remainder of this paper, we describe the proposed approach, after discussing related work. We then present an exhaustive experimental evaluation of its efficiency and scalability in practice. This evaluation employs 17 regression datasets (including one real-world application) and compares our approach to existing ones.
2 Methodology
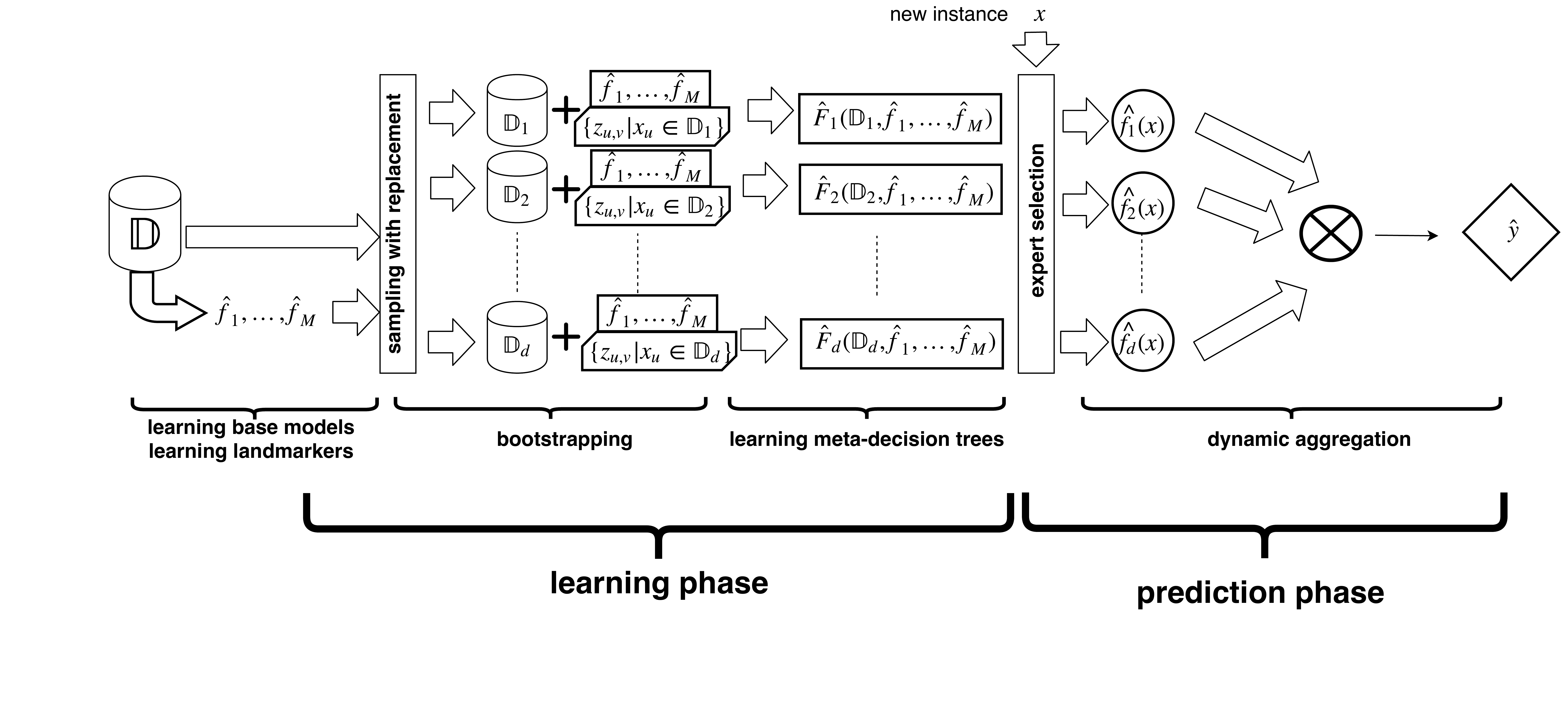
This Section introduces MetaBags and its three basic components: (1) First, we describe a novel algorithm to learn a decision tree that picks one expert among all available ones to address a particular query in a supervised learning context; (2) then, we depict the integration of base models at the meta-level with bagging to form the final predictor ; (3) Finally, the meta-features used by MetaBags are detailed. An overview of the method is presented in Fig. 2.
2.1 Meta-Decision Tree for Regression
2.1.1 Problem Setting.
In traditional stacking, just depends on the base models . In practice, as stronger models may outperform weaker ones, they get assigned very high coefficients (assuming we combine base models with a linear meta-model). In turn, weaker models may obtain near-zero coefficients. This can easily lead to over-fitting if a careful model generation does not take place beforehand. However, even a model that is weak in the whole input space may be strong in some subregion. In our approach we rely on classic tree-based isothetic boundaries to identify contexts (e.g. subregions of the input space) where some models may outperform others, and by using only strong experts within each context, we improve the final model.
Let the dataset be defined as and generated by an unknown function , where is the number of features of an instance , and denotes a numerical response. Let be a set of base models (experts) learned using one or more base learning methods over . Let denote a loss function of interest decomposable in independent bias/variance components (e.g. -loss). For each instance , let be the set of meta-features generated for that instance.
Starting from the definition of a decision tree for supervised learning introduced in CART[6], we aim to build a classification tree that, for a given instance and its supporting meta-features , dynamically selects the expert that should be chosen for prediction, i.e., . As for the tree induction procedure, we aim, at each node, at finding the feature and the splitting point that leads to the maximum reduction of impurity.
For the internal node with the set of examples that reaches , the splitting point splits the node into the leaves and with the sets and , respectively. This can be formulated by the following optimization problem at each node:
| (2) | ||||
| (3) |
where denote the probability of each branch to be selected, while denotes the so-called impurity function. In traditional classification problems, the functions applied here aim to minimize the entropy of the target variable. Hereby, we propose a new impurity function for this purpose denoted as Inductive Bias Reduction. It goes as follows:
| (4) |
where denotes the inductive bias component of the loss .
2.1.2 Optimization.
To solve the problem of Eq. (2), we address three issues: (i) splitting criterion/meta-feature, (ii) splitting point and (iii) stopping criterion. To select the splitting criterion, we start by constructing two auxiliary equally-sized matrices and , where denote a user-defined hyperparameter and the number of meta-features used, respectively. Then, the matrices are populated with candidate values by elaborating over the Equations (2,3,4) as
| (5) |
where is the th splitting criterion for the th meta feature.
First, we find the splitting criteria such that
| (6) |
Secondly, we need to find the optimal splitting point according to the criteria. We can either take the splitting point already used to find or, alternatively, fine-tune the procedure by exploring further the domain of . For the latter problem, any scalable search heuristic can be applied (e.g.: Golden-section search algorithm [22]).
Thirdly, (iii) the stopping criteria to constraint Eq. (2). Here, like CART, we propose to create fully grown trees. Therefore, it goes as follows:
| (7) |
where are user-defined hyperparameters. Intuitively, this procedure consists in randomly finding possible partitioning points on each meta-feature in a parallelizable fashion in order to select one splitting criterion.
The pseudocode of this algorithm is presented in Algorithm 1.
2.2 Bagging at Meta-Level: Why and How?
Bagging [4] is a popular ensemble learning technique. It consists of forming multiple replicate datasets by drawing examples from at random, but with replacement, forming bootstrap samples. Next, base models are learned with a selected method on each , and the final prediction is obtained by averaging the predictions of all base models. As Breiman demonstrates in Section 4 of [4], the amount of expected improvement of the aggregated prediction depends on the gap between the terms of the following inequality:
| (8) |
In our case, is given by the selected by each meta-decision tree induced in each . By design, the procedure to learn this specific meta-decision tree is likely to overfit its training set, since all the decisions envisage reduction of inductive bias alone. However, when used in a bagging context, this turns to be an advantage because it causes instability of - as each tree may be selecting different predictors to each instance .
2.3 Meta-Features
MetaBags is fed with three types of meta-features: (a) base, (b) performance-related and (c) local landmarking. These types are briefly explained below, as well as their connection with the state of the art.
2.3.1 (a) Base features
2.3.2 (b) Performance-related features.
This type of meta-features describes the performance of specific learning algorithms in particular learning contexts on the same dataset. Besides the base learning algorithms, we also propose the usage of landmarkers. Landmarkers are ML algorithms that are computationally relatively cheap to run either in a train or test setting [27]. The resulting models aim to characterize the learning task (e.g. is the regression curve linear?). To the authors’ best knowledge, so far, all proposed landmarkers and consequent meta-features have been primarily designed for classical meta-learning applications to classification problems [27, 3], whereas we focus on model integration for regression. We use the following learning algorithms as landmarkers: LASSO[29], 1NN[10], MARS[15] and CART[6].
To generate the meta-features, we start by creating one landmarking model per method over the entire training set. Then, we design a small artificial neighborhood of size of each training example as by perturbing with gaussian noise as follows:
| (9) |
where is a user-defined hyperparameter. Then, we obtain outputs of each expert as well as of each landmarker given . The used meta-features are then descriptive statistics of the models’ outputs: mean, stdev., 1st/3rd quantile. This procedure is applicable both to training and test examples, whereas the landmarkers are naturally obtained from the training set.
2.3.3 (c) Local landmarking features.
In the original landmarking paper, Pfahringer et al.[27] highlight the importance on ensuring that our pool of landmarkers is diverse enough in terms of the different types of inductive bias that they employ, and the consequent relationship that this may have with the base learners performance. However, when observing performance on a neighborhood-level rather than on the task/dataset level, the low performance and/or high inductive bias may have different causes (e.g., inadequate data preprocessing techniques, low support/coverage of a particular subregion of the input space, etc.). These causes, may originate in different types of deficiencies of the model (e.g. low support of leaf nodes or high variance of the examples used to make the predictions in decision trees).
Hereby, we introduce a novel type of landmarking meta-features denoted local landmarking. Local landmarking meta-features are designed to characterize the landmarkers/models within the particular input subregion. More than finding a correspondence between the performance of landmarkers and base models, we aim to extract the knowledge that the landmarkers have learned about a particular input neighborhood. In addition to the prediction of each landmarker for a given test example, we compute the following characteristics:
- •
CART: depth of the leaf which makes the prediction; number of examples in that leaf and variance of these examples;
- •
MARS: width and mass of the interval in which a test example falls, as well as its distance to the nearest edge;
- •
1NN: absolute distance to the nearest neighbor.
3 Experiments and Results
Empirical evaluation aims to answer the following four research questions:
- 1.
Does MetaBags systematically outperform its base models in practice?
- 2.
Does MetaBags outperform other model integration procedures?
- 3.
Do the local landmarking meta-features improve MetaBags performance?
- 4.
Does MetaBags scale on large-scale and/or high-dimensional data?
3.1 Regression Tasks
We used a total of 17 benchmarking datasets to evaluate MetaBags. They are summarized in Table LABEL:table:usedDataSets. We include 4 proprietary datasets addressing a particular real-world application: public transportation. One of its most common research problems is travel time prediction (TTP). The work in [19] uses features such as scheduled departure time, vehicle type and/ or driver’s meta-data. This type of data is known to be particularly noisy due to failures in the data collection, which in turn often lead to issues such as missing data, as well as several types of outliers [26].
Here, we evaluate MetaBags in a similar setting of [19], i.e. by using their four datasets and the original preprocessing. This case study is an undisclosed large urban bus operator in Sweden (BOS). We collected data on four high-frequency routes/datasets R11/R12/R21/R22. These datasets cover a time period of six months.
3.2 Evaluation Methodology
Hereby, we describe the empirical methodology designed to answer (Q1-Q4), including the hyperparameter settings of MetaBags and the algorithms selected for comparing the different experiments.
3.2.1 Hyperparameter settings.
Like other decision tree-based algorithms, MetaBags is expected to be robust to its hyperparameter settings. Table LABEL:tab:hyperparameters presents the hyperparameters settings used in the empirical evaluation (a sensible default). If any, and can be regarded as more sensitive parameters. Their value ranges are recommended to be and . Please note that these experiments did not included any hyperparameter sensitivity study neither a tuning procedure for MetaBags.
3.2.2 Testing scenarios and comparison algorithms.
We put in place two testing scenarios: A and B. In scenario A, we evaluate the generalization error of MetaBags with 5-fold cross validation (CV) with 3 repetitions. As base learners, we use four popular regression algorithms: Support Vector Regression (SVR)[11], Projection Pursuit Regression (PPR)[17], Random Forest RF[5] and Gradient Boosting GB[16]. The first two are popular methods in the chosen application domain [19], while the latter are popular voting-based ensemble methods for regression [21]. The base models had their hyperparameter values tuned with random search/3-fold CV (and 60 evaluation points). We used the implementations in the R package caret for both the landmarkers and the base learners. We compare our method to the following ensemble approaches: Linear Stacking LS[7], Dynamic Selection DS with kNN[32, 25], and the best individual model. All methods used -loss as .
In scenario B, we use and artificial dataset to assess the computational runtime scalability of the decision tree induction process of MetaReg (using a CART-based implementation) in terms of number of examples and attributes. In this context, we compare our method’s training stage to Linear Regression (used for LS) and kNN in terms of time to build k-d tree (DS). Additionally, we also benchmarked C4.5 (which was used in MDT[30]). For the latter, we discretized the target variable using the four quantiles.
3.3 Results
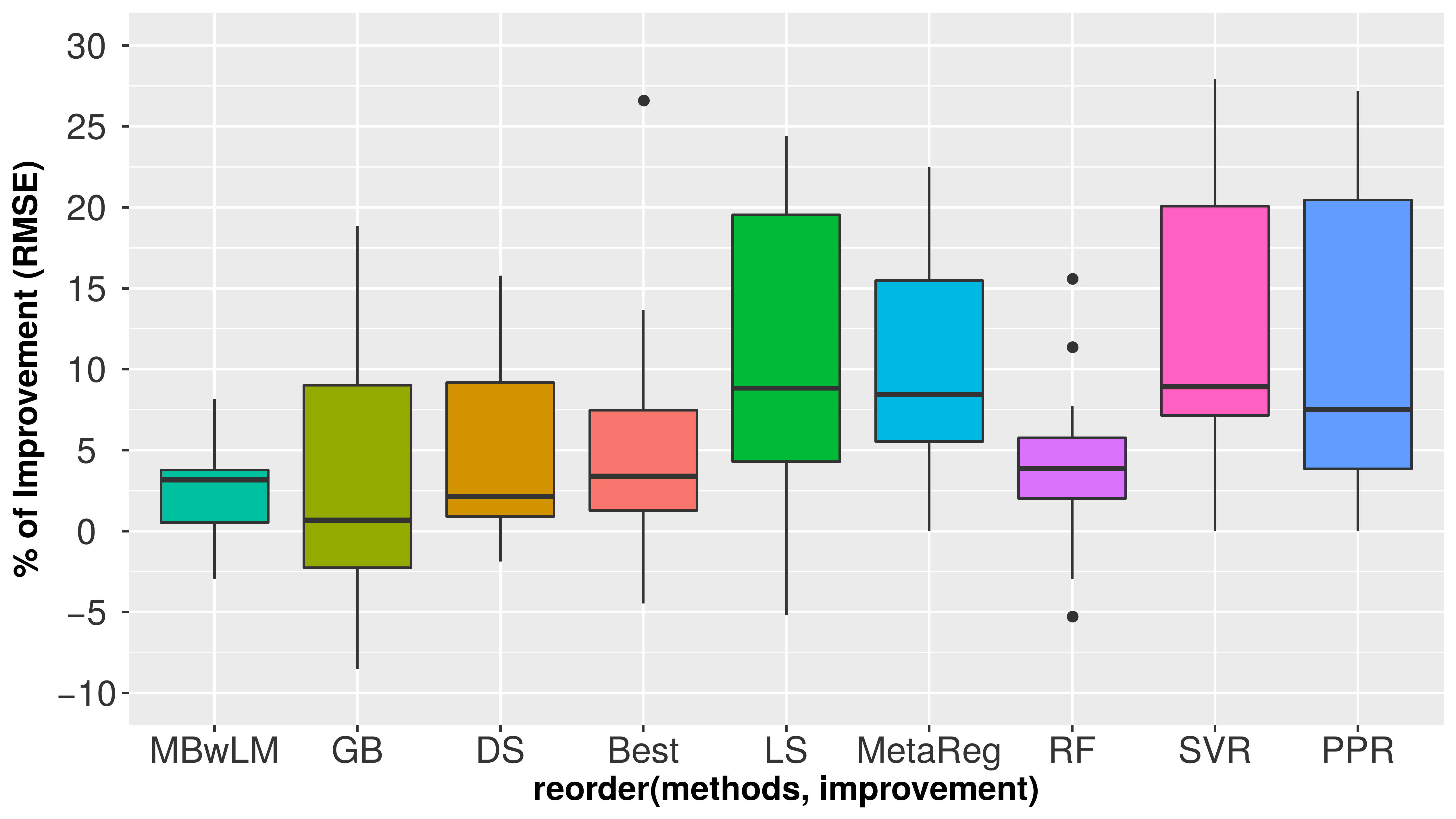
Table LABEL:results_base presents the performance results of MetaBags against comparison algorithms: the base learners; SoA in model integration such as stacking with a linear model LS and kNN, i.e. DS, as well as the best base model selected using 3-CV i.e. Best; finally, we also included two variants of MetaBags: MetaReg – a singular decision tree, MBwLM – MetaBags without the novel landmarking features. Results are reported in terms of RMSE, as well as of statistical significance (using the using the two-sample t-test with the significance level , with the null hypothesis that a given learner wins against MetaBags after observing the results of all repetitions). Finally, Fig. LABEL:fig:summary_results summarizes those results in terms of percentual improvements, while Fig. LABEL:fig:scalability depicts our empirical scalability study.
4 Discussion
The results, presented in Table LABEL:results_base, show that MetaBags outperforms existing SoA stacking methods. MetaBags is never statistically significantly worse than any of the other methods, which illustrates its generalization power.
Fig. LABEL:fig:summary_results summarizes well the contribution of introducing bagging at the meta-level as well as the novel local landmarking meta-features, with average relative percentages of improvement in performance across all datasets of 12.73% and 2.67%, respectively. The closest base method is GB, with an average percentage of improvement of 5.44%. However, if we weight this average by using the percentage of extreme target outliers of each dataset, the expected improvement goes up to 14.65%.
Fig. LABEL:fig:scalability also depicts how competitive MetaBags can be in terms of scalability. Although neither outperforming DS nor LS, we want to highlight that lazy learners have their cost in test time - while this study only covered the training stage. Moreover, many of its stages (learning of base learners, performance-based meta-features, local landmarking) as well as subroutines of the MetaBags are independent and thus, trivially parallelizable. Based in the above discussion, (Q1-Q4) can be answered affirmatively.
One possible drawback of MetaBags may be its space complexity - since it requires to train/maintain multiple decision trees and models in memory. Another possible issue when dealing with low latency data mining applications is that the computation of some of the meta-features is not trivial, which may slightly increase its runtimes in test stage. Both issues were out of the scope of the proposed empirical evaluation and represent open research questions.
Like any other stacking approach, MetaBags requires training of the base models apriori. This pool of models need to have some diversity on their responses. Hereby, we explore the different characteristics of different learning algorithms to stimulate that diversity. However, this may not be sufficient. Formal approaches to strictly ensure diversity on model generation for ensemble learning in regression are scarce [8, 24]. The best way to ensure such diversity within an advanced stacking framework like MetaBags is also an open research question.
5 Final Remarks
This paper introduces MetaBags: a novel, practically useful stacking framework for regression. MetaBags uses meta-decision trees that perform on-demand selection of base learners at test time based on a series of innovative meta-features. These meta-decision trees are learned over data bootstrap samples, whereas the outputs of the selected models are combined by average. An exhaustive empirical evaluation, including 17 datasets and multiple comparison algorithms illustrates the ability of MetaBags to address model integration problems in regression. As future work, we aim to study which factors affect the performance of MetaBags, namely, at model generation level, as well as its time and spatial complexity in test time.
References
- [1] Bell, R., Koren, Y.: Lessons from the netflix prize challenge. Acm Sigkdd Explorations Newsletter 9(2), 75–79 (2007)
- [2] Beygelzimer, A., Kakade, S., Langford, J.: Cover trees for nearest neighbor. In: Proceedings of the 23rd ICML. pp. 97–104. ACM (2006)
- [3] Brazdil, P., Carrier, C. Soares, C., Vilalta, R.: Metalearning: Applications to data mining. Springer (2008)
- [4] Breiman, L.: Bagging predictors. Machine learning 24(2), 123–140 (1996)
- [5] Breiman, L.: Random forests. Machine learning 45(1), 5–32 (2001)
- [6] Breiman, L., Friedman, J., Olshen, R., Stone, C.: Classification and regression trees (cart) wadsworth international group. Belmont, CA, USA (1984)
- [7] Breiman, L.: Stacked regressions. Machine learning 24(1), 49–64 (1996)
- [8] Brown, G., Wyatt, J.L., Tiňo, P.: Managing diversity in regression ensembles. Journal of machine learning research 6(Sep), 1621–1650 (2005)
- [9] Chandola, V., Banerjee, A., Kumar, V.: Anomaly detection: A survey. ACM computing surveys (CSUR) 41(3), 15 (2009)
- [10] Cover, T., Hart, P.: Nearest neighbor pattern classification. IEEE transactions on information theory 13(1), 21–27 (1967)
- [11] Drucker, H., Burges, C., Kaufman, L., Smola, A., Vapnik, V.: Support vector regression machines. NIPS pp. 155–161 (1997)
- [12] Feurer, M., Klein, A., Eggensperger, K., Springenberg, J., Blum, M., Hutter, F.: Efficient and robust automated machine learning. In: NIPS. pp. 2962–2970 (2015)
- [13] Feurer, M., Springenberg, J., Hutter, F.: Initializing bayesian hyperparameter optimization via meta-learning. In: AAAI. pp. 1128–1135 (2015)
- [14] Freund, Y., Schapire, R.: A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences 55(1), 119–139 (1997)
- [15] Friedman, J.: Multivariate adaptive regression splines. The annals of statistics pp. 1–67 (1991)
- [16] Friedman, J.: Greedy function approximation: a gradient boosting machine. Annals of statistics pp. 1189–1232 (2001)
- [17] Friedman, J., Stuetzle, W.: Projection pursuit regression. Journal of the American statistical Association 76(376), 817–823 (1981)
- [18] Gama, J., Brazdil, P.: Cascade generalization. Machine Learning 41(3), 315–343 (2000)
- [19] Hassan, S., Moreira-Matias, L., Khiari, J., Cats, O.: Feature Selection Issues in Long-Term Travel Time Prediction, pp. 98–109. Springer (2016)
- [20] Hastie, T., Tibshirani, R.: Generalized additive models: some applications. Journal of the American Statistical Association 82(398), 371–386 (1987)
- [21] Kaggle Inc.: https://www.kaggle.com/bigfatdata/what-algorithms-are-most-successful-on-kaggle. Tech. rep. (Eletronic, Accessed in March 2018)
- [22] Kiefer, J.: Sequential minimax search for a maximum. Proceedings of the American mathematical society 4(3), 502–506 (1953)
- [23] Lemke, C., Budka, M., Gabrys, B.: Metalearning: a survey of trends and technologies. Artificial intelligence review 44(1), 117–130 (2015)
- [24] Mendes-Moreira, J., Soares, C., Jorge, A., Sousa, J.: Ensemble approaches for regression: A survey. ACM Computing Surveys (CSUR) 45(1), 10 (2012)
- [25] Merz, C.: Dynamical Selection of Learning Algorithms, pp. 281–290 (1996)
- [26] Moreira-Matias, L., Mendes-Moreira, J., Freire de Sousa, J., Gama, J.: On improving mass transit operations by using avl-based systems: A survey. IEEE Transactions on Intelligent Transportation Systems 16(4), 1636–1653 (2015)
- [27] Pfahringer, B., Bensusan, H., Giraud-Carrier, C.: Meta-learning by landmarking various learning algorithms. In: ICML. pp. 743–750 (2000)
- [28] Schaffer, C.: A conservation law for generalization performance. In: Machine Learning Proceedings 1994, pp. 259–265. Elsevier (1994)
- [29] Tibshirani, R.: Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological) pp. 267–288 (1996)
- [30] Todorovski, L., Dzeroski, S.: Combining classifiers with meta decision trees. Machine learning 50(3), 223–249 (2003)
- [31] Torgo, L.: Regression data sets. Eletronic (last access at 02/2018) (February 2018), http://www.dcc.fc.up.pt/~ltorgo/Regression/DataSets.html
- [32] Tsymbal, A., Pechenizkiy, M., Cunningham, P.: Dynamic integration with random forests. In: European conference on machine learning. pp. 801–808. Springer (2006)
- [33] Wolpert, D.: Stacked generalization. Neural networks 5(2), 241–259 (1992)
1. This blog article is an excerpt of the eletronic preprint available at https://arxiv.org/abs/1804.06207. The full article is available as J. Khiari, L. Moreira-Matias, A. Shaker, B. Ženko, and S. Džeroski: MetaBags: Bagged Meta-Decision Trees for Regression, The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD) 2018