Carolin Lawrence Bhushan Kotnis Mathias Niepert
This blog article is related to the article by C. Lawrence, B. Kotnis, M. Niepert, “Attending to Future Tokens for Bidirectional Sequence Generation”, in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019) available at https://www.aclweb.org/anthology/D19-1001
NLP experienced a major change in the previous months. Previously, each NLP task defined a neural model and trained this model on the given task. But in recent months, various papers (ELMo [1], ULMFiT [2], GPT [3], BERT [4], GPT2 [5]) showed that it is possible to pre-train a NLP model on a language modelling task (more on this below) and then use this model as a starting point to fine-tune to further tasks. This has been labelled as an important turning point for NLP by many ([6], [7], [8], inter alia).
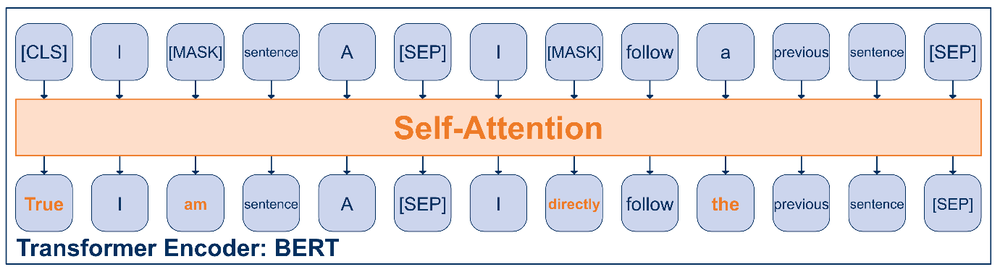
The probably most notorious and popular pre-trained NLP model at the moment is called BERT [4]. Given any type of text (e.g. English Wikipedia article), BERT is a language model that learns to predict words in the given text. Concretely, it is trained as follows: Some sentence is assigned to be Part A and some other sentence is assigned to be Part B. The sentence of Part B may or may not directly follow the sentence of Part A in the original text. Both parts are arranged as follows (also shown in the picture below):
- The sequence starts with a token called: [CLS]
- Part A
- A token called: [SEP]
- Part B
- A token called: [SEP]
The special tokens have specific meanings: [SEP] is a separator token and [CLS] is a token that will be used to predict whether or not Part B is a sentence that directly follows Part A.
To train the language model, 15% of the words in Part A and Part B are masked with the [MASK] token. The model is then trained to correctly predict the missing words.
Concretely, the arranged sequence is given to a transformer encoder. A transformer encoder is a special type of neural network. We will skip the details here and refer the interested reader to the original transformer paper [9]. The most important aspect of a transformer is the self-attention module. In this module, every token in the sequence attends to every other token and a probability distribution is computed that captures how important all the other tokens are to the current one.
BERT is so powerful because it is the first language model that attends not just towards all tokens left of a token but also to all future tokens. This is easily possible because the entire sequence is known from the beginning. This feature is referred to as bidirectional.
Once BERT is trained, it is a pre-trained language model that knows the language (e.g. English) very well. However, it can not solve any other NLP tasks yet. For this, it needs to be fine-tuned to the task of interest, given some supervised training data for this task.
The original BERT paper applies the BERT model to several different NLP tasks, but all of the tasks can be cast as either a sequence classification or a token classification problem.
BERT cannot directly be used as a sequence generation model. This is because its biggest advantage, the bidirectionality, prevents it from being directly used for sequence generation.
Our paper, “Attending to Future Tokens for Bidirectional Sequence Generation” aims to take the best feature of BERT, its bidirectionality, and incorporate it into sequence generation.
Traditionally, sequence generation in sequence-to-sequence problems is performed using an encoder-decoder architecture. An input sentence is encoded using an encoder. The output sequence is then generated token by token using the decoder. Such a framework has been used for various NLP tasks:
- Machine translation: The input is a sentence in one language and the output is its translation in another language.
- Summarization: The input is a long paragraph and the output is its summary.
- Dialogue: The input is the conversation history and the output is the next response in the dialogue.
For sequence-to-sequence tasks, transformers are also the most popular choice of network. (In fact, transformer were first proposed for machine translation before they were applied to language modelling.) When processing the input side, the encoder benefits from the same bidirectionality that makes BERT so powerful: Because the entire input sequence is already known, future as well as past tokens can be taken into consideration.
However, this is not possible for the decoder: Here the transformer has been modified, now called a transformer decoder, to only use its self-attention module over past, already produced tokens. This is a natural approach because it is not possible to attend to something that does not exist yet. But this exactly what we propose to change.
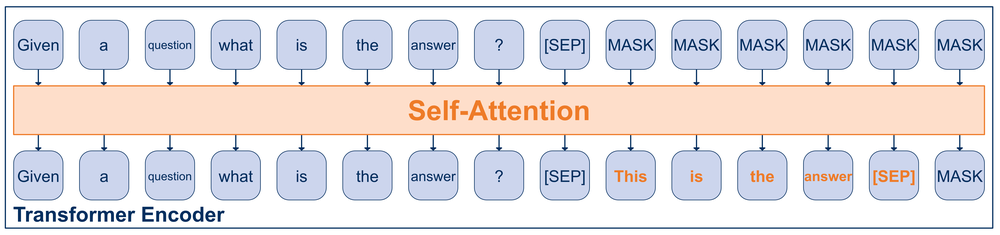
Our approach, Bidirectional Sequence Generation (BiSon), uses a transformer encoder and models future tokens by using a special placeholder token, called [MASK]. This introduces bidirectionality into the sequence generation step.
BiSon follows the same setup as BERT: it has a Part A and a Part B, separated by a separator token [SEP] and another separator token after Part B. Part A holds the input sequence and Part B consists of a sequence of [MASK] tokens. The length of this sequence is some predetermined value, e.g. a sequence of 100 [MASK] tokens will mean that at most 100 words can be produced. BiSon will then replace all [MASK] tokens with words from the vocabulary until it produces the separator token, i.e. it is used to mark the end of the generation sequence.
This process is demonstrated in the picture below:
Experimental Results
Dialogue datasets can generally be grouped into two categories:
- Goal-oriented: There is an ultimate goal that a user wants to accomplish via a dialogue with a system. For example, this could be making a restaurant reservation.
- Free-form: There is no ultimate goal, instead the system aims to keep the user engaged by chatting freely about any topics that arise.
We chose a dataset for each category:
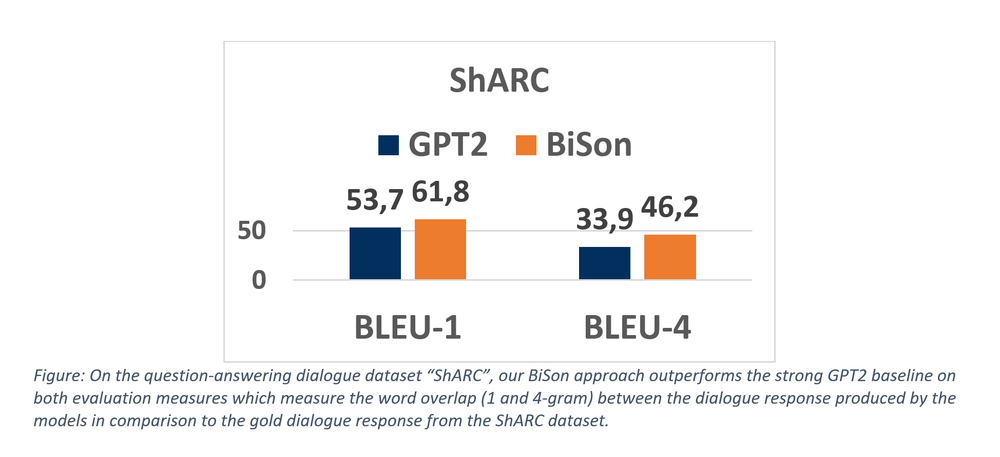
- ShARC [10]: In the ShARC dataset, users need help from a system regarding governmental texts. For an example, see below:

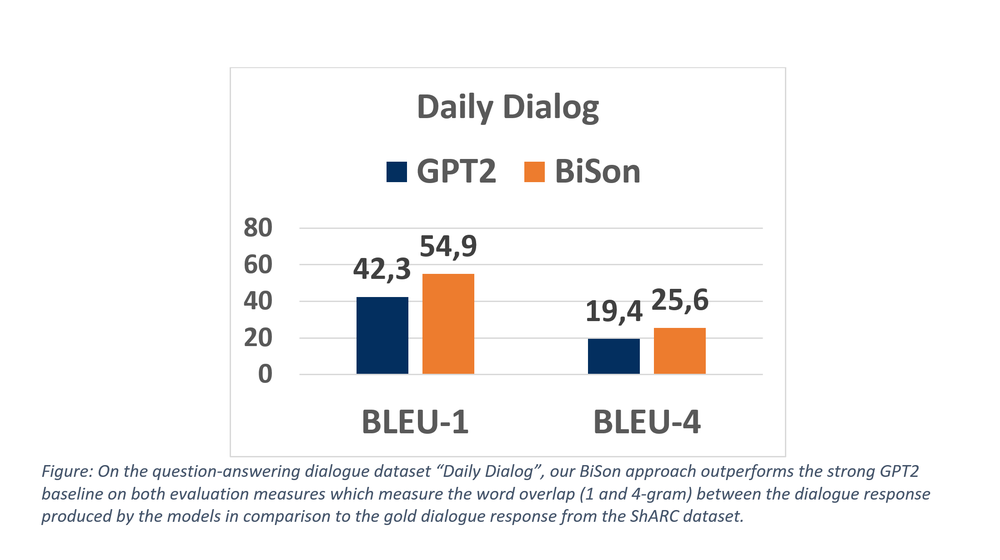
- Daily Dialog [11]: The daily dialog dataset contains written forms of daily conversations.
The clarification questions of ShARC and all outputs of Daily Dialog are evaluate using BLEU-1 and BLEU-4. Both are precision based metrics that measure the n-gram overlap of the model generated response compared to the true human written response. BLEU-1 measure this overlap based on single words (i.e. uni-grams or 1-gram), whereas BLEU-4 uses phrases of length 4 (i.e. 4-grams).
The results are depicted below. For both datasets and both evaluation measures, BiSon outperforms GPT2 by a large margin.
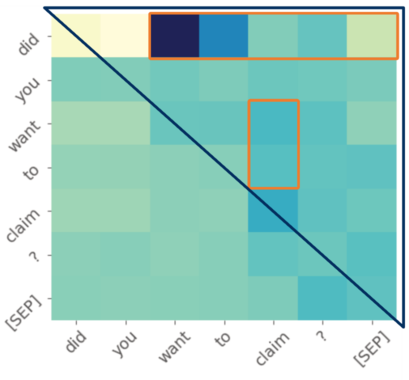
Attention to Future Tokens
Our model, BiSon, can attend to future tokens, even if they aren’t produced yet. Below we visualize for our transformer encoder the attention every word in a sentence pays to every other words, both present and future (the darker the colour, the more attention is paid). The example was produced going from left to right, so the upper right triangle marks the attention paid to future tokens.
We can see that when deciding on the first word, “did”, high attention is paid to important future tokens. In particular, there is a strong focus on the 3rd placeholder, which is later revealed to be “want”. Attention is also paid to the position that is later revealed to become a question mark. This indicates that model plans ahead and realizing a question will be formed, the word “did” is chosen. Note that the similar sentence, “you want to claim.” would not require the word “did” as it would not be a question. Also in Figure 3, both the words “want” and “to” pay strong attention to the final word “claim” in the phrase “want to claim”.
Summary
We presented BiSon, a novel method to generate sequences by attending to future tokens. This introduces bidirectionality into sequence generation, which is a crucial feature in the recently proposed and very successful language model BERT. Our model can directly load this pre-trained BERT model. Furthermore, it is not bound to generate the output sequence from left to right. All three features leads to large improvements for sequence generation, as we have demonstrated on two dialogue datasets.
References
[1] Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, Louisiana.
[2] Jeremy Howard and Sebastian Ruder. 2018. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia.
[3] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving Language Understanding by Generative Pre-Training. Technical Report Technical report, OpenAI.
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of
deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota.
[5] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, and Dario Amodei. 2019. Language Models are Unsupervised Multitask Learners. Technical report, OpenAI.
[6] Sebastian Ruder. 2018. NLP's ImageNet moment has arrived. The gradient. https://thegradient.pub/nlp-imagenet/ (accessed 28 October 2019)
[7] Shreya Ghelani. 2019. From Word Embeddings to Pretrained Language Models — A New Age in NLP — Part 2. Towards Data Science. https://towardsdatascience.com/from-word-embeddings-to-pretrained-language-models-a-new-age-in-nlp-part-2-e9af9a0bdcd9 (accessed 28 October 2019)
[8] Mariya Yao. 2019. What Every NLP Engineer Needs to Know About Pre-Trained Language Models. Topbots. https://www.topbots.com/ai-nlp-research-pretrained-language-models/ (accessed 28 October 2019)
[9] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz
Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems 30 (NIPS).
[10] Marzieh Saeidi, Max Bartolo, Patrick Lewis, Sameer Singh, Tim Rocktäschel, Mike Sheldon, Guillaume Bouchard, and Sebastian Riedel. 2018. Interpretation of natural language rules in conversational machine reading. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP).
[11] Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu. 2017. Dailydialog: A manually labelled multi-turn dialogue dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (IJCNLP), Taipei, Taiwan.